为何AI仍未取代我们

毫无疑问,这两年最热门的话题无疑是 AI,我记得大概在 2020 年问过一位研究 AI 的朋友,什么时候 AI 会替代程序员的工作,那时他说很难。没想到 2022 年 OpenAI 的 ChatGPT 横空出世,举世震惊,好像全世界都没有做好心理准备的情况下,AI 的拐点就突然出现在我们面前,一夜之间犹如科幻照进现实。惊叹之余,当时讨论最多的话题有哪些工作最容易被 AI 取代,或者 AI 什么时候会取代人,要么是做哪些工作最不容易被 AI 取代,史称“第一次牛马危机”。时至今日,三年过去了,虽然让人担心的巨大裁员并未发生,但 AI 何时取代人的工作这个话题依然在热烈讨论,恰逢过去两年确有不少公司裁员,多则几千人少则几十上百人,裁员的主要原因不见得是 AI 的出现导致的。这里有一个大的背景不应该被忽视,大瘟疫时期的低利息环境让许多公司轻松融资,不少公司非理性投资和扩编人员,造成人员过度冗余,公司运营效率降低,疫情结束之后,为抑制通胀,各国央行执行升息政策,经济环境恶化,公司利润下滑,公司希望通过或多或少的裁员来降低运营成本来提高利润。这时 AI 的适时出现,恰好和公司的裁员需求碰上,甚至还有公司推出 AI 产品号称能代替人工,此时 AI 转型给公司 CEO 们提供一个战略级的裁员理由,也不晓得以 AI 之名裁员的公司最后用上 AI 产品来代替人工了吗?
现在 AI 的发展处于方兴未艾的阶段,时刻都有新的名词和新概念被发明出来,AI agents,MCP,RAG, LangChain 等等,这些新概念本质上关注如何有效应用 AI 来解决现有的问题。当然应用对产业发展至关重要,如果不能应用,产生不了价值,这个产业便不可持续的吸引投资和人才。但这些新的概念并非 AI 取代人的关键,核心还是目前 AI 的原理。所以我想看看当前 AI 原理来探讨目前 AI 对取代人类的可能。
AI 处于什么阶段
理论上,AI 的发展会经历三个阶段,弱 AI(Weak AI, Narrow AI)简称 ANI,强 AI(Strong AI)也叫 AGI,超级 AI(Artificial Super Intelligence),简称 ASI。
虽然我们感觉现在的 AI 已经很强大了,但是 AI 还尚处在弱 AI 的阶段。因为当前的 AI 模型都是训练出来解决某些特定范围内的问题,也可以说 AI 模型的训练的数据是巨量的有明确答案的数据,一旦尝试靠它来解决训练范围之外的问题时就显得不太灵光了。有时对我们的提问,AI 的回答就似胡编乱造(hallucination),即便你告诉它如果你不知道请说不知道,可是 AI 从不承认自己的无知,这并非 AI 不愿承认,而是它不清楚自己找到的答案并不正确,这难免让人怀疑 AI 是否真的有推理能力。也许 AI 给我们造成的压迫感,更多还是由于大语言模型在知识储量上绝对胜过任何人类个体,毕竟它们学遍了整个互联网上公开的知识,但知识量的碾压并不能代表智力上的碾压。
下一步,来到强 AI (AGI)阶段,或者叫通用 AI,这类 AI 能够处理问题的能力没有范围限制,并且会不断的自我学习和自我进化,到那个时候,AI 的能力无限接近接近人类。
最后,来到超级 AI(ASI)阶段,那时的 AI 超越人类所有的优点,拥有自我意识,显而易见最大的风险在于一旦它真的出现,人类有能力去掌控它吗?
当前的 AI
人工智能(AI)的概念在电子计算机发明不久的 1950 年代就被 John McCarthy 提出了,他深信计算机除了完成计算,应该还能做的更多,计算机能学习并具备所有智慧的功能(“Every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”),通俗地说,就是让计算机拥有与人一样学习和思考的能力。经过几代人几十年的探索,当前实现 AI 的路径大致是从机器学习到神经网络到深度学习到现在的大语言模型,像剥洋葱一层一层被探索出来,这条路径能否带领我们走向 AGI 和 ASI 并不确定。

机器学习(machine learning),简单来说就是让机器使用算法去学习我们提供的训练数据从而寻找数据里的规律(pattern),然后让机器用找到的规律来识别新的数据并做出预测和判断。这样做相较于一般的基于规则编写的计算机程序,虽然牺牲了一些准确性,并且还存在结果不可预测性,但得到了更好的灵活性,在现实世界里,很多场景是不可能完全靠人力来提前预设所有变量并制定相应规则,图像识别是一个经典的例子,也就是说机器学习为我们提供了一个当前主流的基于规则系统(Rule Based System)之外的选择。
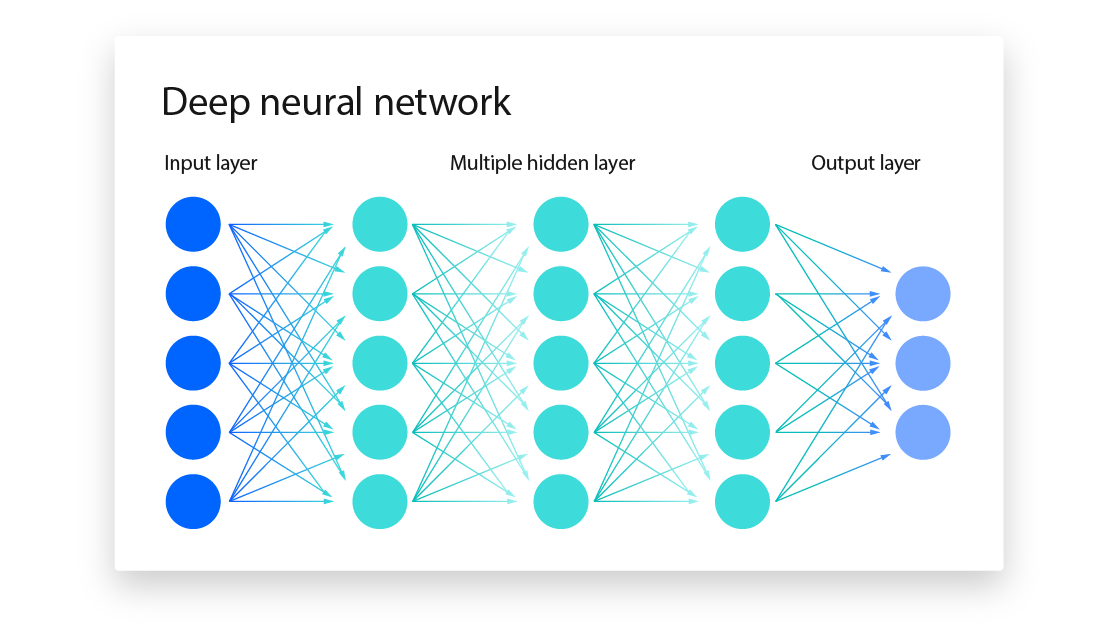
机器学习有不同的实现方法,神经网络(neural networks)是其中之一,作为一种模型框架,它的诞生受到人脑生物神经元(neuron)的启发。机器学习里的神经元的概念并不复杂,每个神经元带有三个关键的值。
- 激活值(activation),这是一个从 0 到 1 的值,每一个神经元的激活值都由上一层所有神经元的激活值作为输入变量决定。
- 权重(weight)代表当前层次某个神经元与上一层每个神经元之间联系的强弱,上一层每个神经元与当前这个神经元有一个单独的权重。假如上一层有 20 个神经元,那么在当前层每个神经元与上一层都有 20 个权重。
- 偏置项(bias),相当于激活神经元各自需要的门槛值。
一个神经网络由多层(大于 3 层)的神经元构成,第一层接收数据的输入,然后各层之间单向传递数值,在传递过程中,每个神经元对输入的数值计算之后得到一个新的数值又传递给下一层的神经元,直到最后一层神经元,最后一层里激活值最高的那个神经元就是神经网络给出的结果。计算过程是上一层每个神经元的激活值乘以相对应的下一层神经元权重,然后求和,在加上偏置项,就得到下一层神经元的激活值,如此层层递进计算。这个过程的计算方程如下
\[y = f\left(\sum_{i=1}^{n} w_i x_i + b\right)\]由此可知,所谓的”学习”,实质上在给神经网络寻找一套正确的权重和偏置项,也是我们常听说的参数,把这些学习获得的参数保存下来就是模型。换个角度看,每个神经元是一个函数,这个函数自带两个常量(权重和偏置项),它接收一个变量作为输入然后输出一个结果(激活值),把这个结果作为输入参数投入下一个神经元函数,层层递进直到结束。一般来说,神经网络的神经元越多效果越好,当然参数自然也越多。一个普通的识别图片上 0 到 9 数字的模型参数规模都能上万,现在一个大语言模型的参数规模普遍达到百亿到万亿级别,因此各家厂商在宣传自己模型性能时都会强调参数的大小。
想要找到这套正确的参数,通过一种叫做反向传播(Backpropagation)的操作来实现,如果我们把变量输入到神经元得到一个激活值,然后把激活值作为下一个神经元的变量输入得到下一个激活值,依次递进直到最终结果的过程称为正向传播,那么反向传播就是把顺序反过来,从已知结果来层层倒推反向寻找每个神经元正确的参数(权重,偏置项),这个过程用微积分(Calculus)方程来计算。
这种通过反向传播训练神经网络原理早在 1970 年代便存在了,在 1980 年代在 David Rumelhart, Geoffrey Hinton, Ronald Williams 的推动下被主流接受。即使数学上的理论有了,可是在实践过程中研究者们遇到很多挫折,受限于早期神经网络架构(CNN,RNN)的设计,只能使用串行计算来进行模型训练,导致训练速度的上限很低,在数据量小的时候,训练耗时还能接受,一旦投喂大量的数据来做训练,训练耗时会达到无法接受的程度,由于无法进行大规模训练,也因此没有机会诞生大模型。另外不能理解全局上下文也是早期架构的一个重要缺陷,你是否记得早期的苹果 Siri 几乎只能完成一句话的聊天,完全不能进行多个来回的对话。再加上早期架构的一些其他缺陷使得人工智能领域一直没能推出让人满意的产品。
模型不能直接理解人类语言,为了让模型理解人类语言,要先把文字(word)切分成令牌(token),用令牌去嵌入矩阵(embedding matrix)中找到对应的向量(vector),嵌入矩阵相当于是一本巨大的向量字典,每个文字都有提前计算好的向量,通过把文字变成向量,模型便能理解文字了。接下来,这些向量会依次经过模型内部的其他矩阵(matrix)运算,每一层矩阵都是在经过训练学习出来的,也就是神经网络的各层。向量经过层层矩阵的传递之后,模型会输出一个对整个词表(vocabulary)所有令牌的分数向量(logits)。经过 softmax 计算转换成概率后,取概率最高的令牌作为输出。
关于向量,也叫矢量,简单说是有方向的数值,还记得我们在初中物理学习受力分析时肯定接触过向量的概念,力的大小仅是一个数值,受力分析最重要的是考虑力的方向,这就是说,力的数值需要力的方向来赋予意义,一个没有方向的纯数值是没有意义的。不过当时学习受力分析的向量只有两个维度,而机器学习里的向量有上万个维度,但道理并无二致,都是通过方向为数值赋予意义。因此我们可以理解为,如果有两个向量在某个维度的方向上一致,那么它们在某个维度上的意义就是相关的,如果它们在更多的维度上方向一致,它们之间的关联就越强,如同披萨之于意大利,寿司之于日本。
在此期间,尽管没有诞生出如 GPT 那样世人皆知的产品,但 Google AlphaGo 在围棋这项曾经被认为机器绝不可能战胜人类的领域击败了世界上最厉害的棋手,表明机器学习界已然取得了重大的进展,摸索出了模型训练和使用的基本架构,发明了至今我们耳熟能详的概念,因此计算机界最高奖的图灵奖(Turing Award)有 7 次授予 AI 方面的研究。
临门一脚发生在 2017 年,大名鼎鼎的 Google Transformer 架构随着那篇著名的论文 Attention Is All You Need 一起出现,改变了 AI 界乃至世界的发展轨迹。Transformer 架构带来的注意力(attention)机制和并行计算是诞生大模型并让 AI 成为受欢迎产品的关键,这两项发明克服了早期架构无法知晓全局上下文和训练速度慢的缺陷。
注意力机制中的“注意力”这个词用的非常巧妙,这个词原本表示人聚焦在自身的某种感知来获取自身周围环境信息行为,让我想起上课走神时,老师提醒我集中注意力听课,使用注意力这个词暗示了这种机制在模仿人感知周围信息的行为。注意力机制的目的在回答一个核心问题,就是作为一个令牌(token),我这个令牌应该把注意力放在周围的哪些令牌上,放多少?当回答了这个问题,我们便知这个令牌和周围其他令牌的联系。这个过程通过给每个令牌计算三个向量完成。
-
向量 Q(Query) - 我要找什么?
这个问题包含了许多子问题,例如我是一个名词,那我前面有形容词吗?如果我是一个代词,那我要代表的名词是什么?诸如此类的预设问题存在一个矩阵(matrix)中,一个维度代表一个子问题,用这个问题矩阵乘以这个词的向量便得到向量 Q,向量 Q 便是有关这个词的问题集合。
-
向量 K(Key) - 我能提供什么?
向量 K 的作用在于回答向量 Q 的问题,但为了回答 Q 的问题,令牌需要问自己一堆问题,比如我是一个形容词吗?我是一个名词吗?同样预设问题存在一个矩阵(matrix)中,一样的乘法操作便得到向量 K。
每个令牌的向量 Q 和其他令牌的向量 K 交叉对比便能得知每个令牌之间的关系亲疏。这里需要的计算量很大,比如一句话有 10 个词,先计算每个词的向量 Q 与向量 K,然后用每个词的向量 Q 和向量 K 交叉计算,交叉计算需要 100 次,如果是 100 个词,那就要计算 10000 次,计算量随着上下文(context)长度呈指数增长,所以上下文的长度成为大语言模型的瓶颈。
-
向量 V(Value) - 在上下文中,我带来的实际信息。
既然知道了每个令牌之间的关系亲疏,那么把与我和与我相关的其他令牌的意义(向量)叠加在一起便是我在全局中能贡献的实际意义(向量 V),比如一个名词找到相关的形容词放在一起的之后得到的新意义,也就是说,我原本的词意被赋予了上下文的意义。
以上过程叫自注意力机制,公式如下
\[\text{Attention}(Q, K, V) = \operatorname{softmax}\!\left( \frac{QK^{\top}}{\sqrt{d_k}} \right) V\]在 transformer 架构中,一次注意力计算叫单头注意力(single head of attention),单头注意力只能关注一种语法模式,而多个头合起来叫多头注意力(multi-headed attention)。
举个例子,“我昨天在图书馆遇到了一位很久没见的朋友。”
第一个头负责处理时间关系
我 → 昨天
遇到 → 昨天
第二个头负责处理位置关系
遇到 → 图书馆
第三个头负责处理名词和形容词关系
朋友 → 很久
朋友 → 没见
第四个头负责主语和动词关系
遇到 → 我
第五个头名词和数量关系
朋友 → 一位
多头注意力就像有多个“聚光灯”同时照亮句子的不同语法关系,从而完整理解句子的结构和含义,而且多头注意力的运算是并行的,因此多头注意力的运算并不比单头注意力运算慢。实际的架构中头数更多,例如 GPT-3 有 96 个头。经过多头注意力的计算之后得到“理解了上下文”向量,然后把该向量投入模型之中,经过模型神经网络的层层传递,最后选取可能性最高的令牌作为预测结果。其中的过程我省略了很多步骤和结构。
综上所述,神经网络就是进行概率预测,Transformer 架构的出现,使模型具备了理解上下文的能力,从而能够预测语言。看似神奇的效果并非魔法,只是海量的参数与复杂结构,使得模型的预测机制难以被我们完全解释。
缺少价值观
科技公司 Anthropic 在 2025 年 3 月搞了一个用 AI 模型来做生意的实验,他们用自己研发的 AI 模型 Claude 经营公司内部的一台冰箱作为自动售货机,Claude 要负责维护库存,商品定价,打折促销,根据顾客需求下订单等等事务,最终目标是实现盈利。经过一个月的自主经营,最终结果是生意破产。对 Claude 的表现,Anthropic 认为有亮点也有失误,虽然 Anthropic 没有解释失误的原因,比如有人出价$100 买一件商品,商品进价$90,它却表示以后考虑,于是错失商机;另外它给商品定价比进货价低,它还被顾客忽悠给出亏本的折扣。这些行为难道是它不会做简单的算术吗?我认为由于缺乏价值观导致它不能正确评估交易的价值,也不能评估顾客的真正意图,进而不能做出正确的商业判断,即便一开始开发人员已经给它定下了目标和原则。放到更大的尺度上看,道德和价值观是人类社会活动进行的基础,它们并非是一系列固定的规则,也不存在统一的标准答案,反而是动态且充满矛盾的,可是一旦缺少它们,无论是人还是 AI 都会做出不合适的行为,或者说反社会的行为。
不会提问
当人与人之间对话时,如果人类面对自己不了解的话题,他们会通过提出一个又一个的问题来一步步接近答案,因此对人来说,能正确提问是一个非常重要的能力。在我们与 gpt 类的 AI 的交谈中,你觉得它们会像人那样提问吗?我的体验是它们要提问,但更像一个助理那样确认下一步要它做什么,而不是人与人之间的对话那样在探讨。行为上它们仍然是一种高级的问答机(question answering),这或许也是人类对它们的定位,我印象中科幻电影里“好”的 AI 大概都是如此,仅仅对人发起的需求提出响应,而扮演反派的“坏” AI 则表现的更有自我意识。不管是好是坏,一个真正的智慧体,它知道的东西越多,随之而来它提出的问题应该越多。假设有一个人学习了互联网上所有公开知识,想必这个人会提出非常多的问题。
被取代的
既然目前人没有被取代,有什么被 AI 取代了呢?搜索引擎作为访问互联网巨量信息的主要入口,曾经的地位是垄断的,随着移动互联网时代的来临,各式各样手机 APP 逐渐分走了用户流量,甚至于有些出生在移动互联网时代的用户习惯在遇到需要解决的问题时的反应是到手机应用商店找寻合适的应用而不是打开搜索引擎。在 GPT 类的应用推出以后,现在很多用户在遇到问题时的习惯变成先问 AI,毕竟自己去从头的搜索和梳理信息来匹配自己的需求是一个耗时耗力的过程,而大语言模型已经学遍了互联网的公开信息,索性直接去问 AI 更省时省力。更糟的是,不仅是搜索引擎的访问量受到了冲击,知识问答类网站的访问量也下降许多,由于提问量的大幅下降,知识问答类社区的参与度也在下降,全世界最大的程序员问答社区 Stack Overflow 的单月提问量相比峰值时已降低了 60-77%,我自己估计已有半年没去 Stack Overflow 查找问题了。一方面这些 Web 2.0 时代靠用户生成内容建立起来的知识储备库正被 AI 模型训练迅速抽干,另一方面新的高质量内容难以按照消耗速度来补充。雪上加霜的是,现在 Google 搜索引擎也推出了 AI 概览(AI Overviews)来总结搜索结果的内容,如此一来用户不再逐条去查看搜索结果链接的网站便能知晓大致的内容,但这样却会极大削弱网站的流量,而流量是很多网站生存至关重要的因素。
路在哪里
有关 AI 的众多讨论中,有人质疑 AI 发展对社会带来的负面影响,也有人认为科技进步最终都会造福人类。甚至有人把大语言模型(LLM)的诞生比做第二次世界大战原子弹的诞生,原子弹这种原本用来摧毁敌人的毁灭性武器也能转变成有益人类的能量之源,试图用这种比喻来打消人们对 AI 的顾虑。先抛开利弊,二者的区别在于原子弹的诞生是建立在相对论质能方程(E = mc²)的发现,这是理论物理学的一次重大突破,也是人类认知维度的提升。即便此次 AI 领域的突飞猛进得益于好几项图灵奖级别的研究,但目前的成就并非任何诺贝尔奖级别的研究成果的转化,也就是缺乏基础科学的研究突破,或许 AI 领域更大更深远的突破需要的是基础科学的突破,比如生物学上的神经科学研究。机器学习中神经网络的工作原理是受到神经科学的赫布理论启发,但反过来机器学习的神经网络能用来解释真正的神经网络吗?
Neurons that fire together wire together. 一起激活的神经元,会彼此强化连接。
From Hebbian theory 赫布理论
也许在更重大的理论突破出现之前,大公司和大国的 AI 技术壁垒仍靠把持 GPU 的数量和技术代差来维持,而小公司小国家无法轻易获得和负担巨量的计算规模,就如同核武器的真正壁垒并不在理论而在大国对核原料的垄断。
科技以人为本
“科技以人为本”,初识这句标语是在诺基亚手机的广告中,虽然诺基亚手机不幸成为了时代的眼泪,但这句广告语却历久弥新。它的英文“Connecting People”直译为“连接人与人”,尽管直译版本一语双关,既表达手机的功能也表达通讯公司的社会职责,不过我更欣赏广告语中的翻译,体现出更高的人文境界,科技发展的目的是造福人,而不应该是取代人。随着科技的进步,我对这句标语的认同愈发深切,人类切莫在追求极致效率的路上忘记了自己。

后记
距离这篇文章开始提笔已然两个月了,我自知不是一个写东西很快的人,但没料到花了这么长时间。在此期间,AI 领域肯定出现了许多新的变化,据说 Google Gemini 的表现领先其他对手,对此我毫不意外,毕竟目前 AI 的两个重要里程碑,AlphaGo 和 Transformer 架构都是 Google 达成的,不论在 AI 的学术还是工程领域 Google 都有深厚的积累,只不过前一段时间他们在产品领域被其他公司打了一个时间差。我并非 AI 领域的专业人员,甚至连爱好者都算不上,文章中关于各种原理的解释肯定有不少纰漏,想法上定有不成熟的地方,望各位不吝赐教,同时我也感谢 AI 给我解释了不少陌生的概念。